
機械学習を始めると、「どのモデルを使えばいいの?」という壁に誰しもぶつかる。Random Forest が強い、とか SVM が安定している、という話はよく聞くが、同じデータ・同じ前処理・同じ評価条件 で並べて比較した記事は意外と少ない。今回はその疑問に答えるべく、scikit-learn の代表的な分類器10種類を徹底比較した。
実験の概要
| 項目 | 内容 |
|---|---|
| データ | load_breast_cancer()(569サンプル・30特徴量・2値分類) |
| 分割 | train 80% / test 20%(stratify あり) |
| 前処理 | StandardScaler を Pipeline に組み込み |
| 評価指標 | Accuracy・ROC-AUC・学習時間 |
使用したのは scikit-learn の乳がん診断データセット(Breast Cancer Wisconsin)。悪性/良性の2値分類で、特徴量は腫瘍の半径・テクスチャ・面積など30種類の統計的指標だ。サンプル数569・テストセット114という小中規模のデータで、「きれいなデータでモデルのポテンシャルを純粋比較する」 というのが今回の狙い。
環境構築
以下のコマンド一発で必要なライブラリがすべて揃う。
pip install scikit-learn pandas matplotlibあとは Python 3.8 以上があれば動作する。Jupyter Notebook や Google Colab でもそのまま実行可能だ。
データ準備とモデル定義
前処理は全モデルで共通にするため、Pipeline で StandardScaler を挟んでいる。これにより「前処理を忘れて比較してしまう」というミスを防げる。
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
data = load_breast_cancer()
X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
stratify=y を指定しているのがポイントで、分割後も train/test でクラス比率が揃うよう保証している。乳がんデータは悪性:良性が約37:63と偏りがあるため、これを指定しないとたまたま test に悪性が集中するといった運任せの評価になってしまう。random_state=42 は再現性確保のためのおまじないで、値自体に深い意味はない。
比較したモデルは以下の10種類。ハイパーパラメータはデフォルト設定をベースラインとした(チューニングは別記事で扱う予定)。
models = {
"Logistic Regression": LogisticRegression(max_iter=5000),
"Linear SVM": SVC(kernel="linear", probability=True),
"RBF SVM": SVC(kernel="rbf", probability=True),
"k-NN": KNeighborsClassifier(),
"Decision Tree": DecisionTreeClassifier(random_state=42),
"Random Forest": RandomForestClassifier(random_state=42),
"Extra Trees": ExtraTreesClassifier(random_state=42),
"Gradient Boosting": GradientBoostingClassifier(random_state=42),
"AdaBoost": AdaBoostClassifier(random_state=42),
"Naive Bayes": GaussianNB(),
}線形系(Logistic・Linear SVM)、カーネル系(RBF SVM)、近傍法(k-NN)、木系(Decision Tree・Random Forest・Extra Trees・Gradient Boosting・AdaBoost)、確率モデル(Naive Bayes)とアプローチが異なる10種類を揃えた。probability=True を SVC に指定しているのは、後で ROC-AUC を計算するために確率スコアが必要なため。これを忘れると predict_proba() でエラーになる。
学習・評価ループ
Pipeline を使うことで、StandardScaler の fit が必ず train データだけで行われる。もし Pipeline を使わずに先に X 全体をスケーリングしてから分割してしまうと、test データの統計情報が train 時に漏れてしまう(いわゆる データリーク)。精度が実態より高く見えてしまうため、この構造は地味だが重要なポイントだ。
time.time() で学習時間を計測しているが、あくまで単回測定なのでノイズが大きい点は注意。目安程度に見てほしい。
import time
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score, roc_auc_score
results = []
for name, model in models.items():
pipeline = Pipeline([("scaler", StandardScaler()), ("model", model)])
start = time.time()
pipeline.fit(X_train, y_train)
train_time = time.time() - start
y_pred = pipeline.predict(X_test)
y_prob = pipeline.predict_proba(X_test)[:, 1]
acc = accuracy_score(y_test, y_pred)
auc = roc_auc_score(y_test, y_prob)
results.append({
"Model": name,
"Accuracy": acc,
"ROC-AUC": auc,
"Train Time (s)": train_time
})
結果と考察
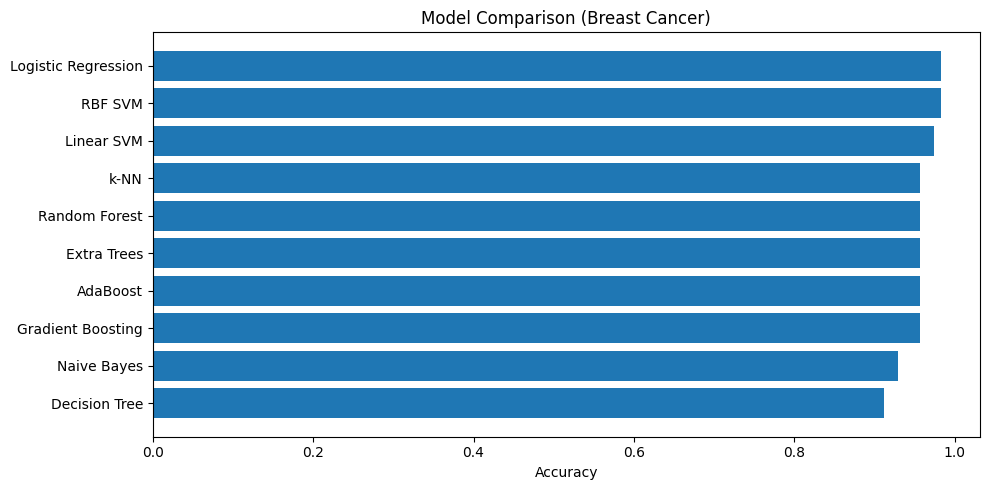
Accuracy ランキング
| Model | Accuracy | ROC-AUC | Train Time (s) |
|---|---|---|---|
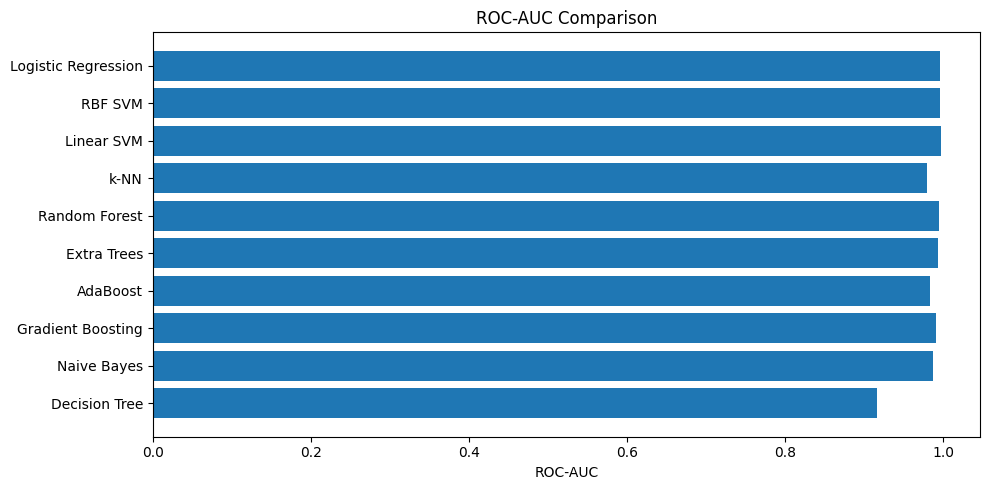
| Logistic Regression | 0.9825 | 0.9950 | 0.05 |
| RBF SVM | 0.9825 | 0.9944 | 0.02 |
| Linear SVM | 0.9737 | 0.9960 | 0.10 |
| Extra Trees | 0.9737 | 0.9939 | 0.15 |
| Random Forest | 0.9649 | 0.9944 | 0.25 |
| Gradient Boosting | 0.9649 | 0.9938 | 0.80 |
| AdaBoost | 0.9561 | 0.9916 | 0.15 |
| k-NN | 0.9561 | 0.9888 | 0.01 |
| Naive Bayes | 0.9386 | 0.9922 | 0.01 |
| Decision Tree | 0.9298 | 0.9225 | 0.01 |
※ 上表は実験環境による参考値。Train Time は特に実行環境依存。


「なぜ Logistic Regression が強いのか」という疑問
正直に言うと、最初は 「Logistic Regression ごときが SVM や Random Forest に並ぶはずがない」 と思っていた。しかしよく考えると、これは納得できる結果だ。
Breast Cancer データセットの特徴量は、腫瘍の半径・面積・凹面などを手作業で設計した統計指標であり、もともと分離しやすくなるよう情報を凝縮してある。つまり、生のピクセルデータや時系列データとは異なり、線形分離に近い構造が最初から埋め込まれている可能性が高い。Logistic Regression がシンプルな線形境界でも十分機能するのはそのためだろう。
「複雑なモデルが常に良い」という思い込みは危険だ、と改めて感じた。
AUC 最高は Linear SVM ── Accuracy との違いをどう解釈するか
ROC-AUC が最も高いのは Linear SVM(≈0.996)で、Accuracy トップの Logistic Regression より高い。これは「スコアの並べ替え精度が高い」ことを意味し、閾値を変えたときに柔軟に感度と特異度のトレードオフを操作できる ことを示している。
医療の場面ではこの違いが非常に重要になる。乳がん診断なら「見逃し(偽陰性)を最小化したい」という要求が強い。その場合、単に Accuracy が高いモデルを選ぶより、AUC が高いモデルを選んで閾値を下げる運用の方が、実際のリスク管理に適している場面が多い。
「モデル選択 ≠ 指標の最大化」という視点は、実務で常に意識しておきたい。
Decision Tree は下位だが「負け方」に注目
Decision Tree は Accuracy・AUC ともに最下位に近い結果だったが、ROC-AUC が 0.92 に留まった点は興味深い。これは他のモデルと比べてスコアの分布が粗いことを意味しており、単純な木構造の確率推定の限界が出ている。一方、学習・推論が高速で解釈性が高いため、ルールを人間が確認しながら運用したい場面 では依然として有力な選択肢だ。
「差が小さい」ことの危うさ
上位モデルの差はテスト114サンプルにおいてわずか2〜3サンプルの違いに相当する。これを「Logistic Regression が最強」と断言するのは早計だ。本来は k-Fold Cross Validation で平均±標準偏差を比較し、その差が統計的に意味あるものかを確認すべきだ。今回はベースライン比較のため単回測定としたが、次のステップとしてCV比較を行うことをお勧めする。
実務向け推奨まとめ
筆者が実際の現場でこのデータに向き合うなら、こういう順序で考える。
Step 1: まず Logistic Regression をデプロイ候補にする 解釈性(係数)・推論コスト・メンテナンス性のバランスが最も良く、精度もトップクラス。説明が必要な医療・金融領域では特に有利。
Step 2: 感度が不足するなら閾値調整 モデルを変えなくても、閾値を 0.5 から下げるだけで偽陰性を大幅に減らせる。まずここを試す。
Step 3: それでも足りないなら RBF SVM か Random Forest を軽くチューニング デフォルト設定でも十分強いが、C や n_estimators を少し調整するだけで改善余地がある。
Step 4: エッジデプロイや推論速度が重要な場合 k-NN は学習が速いが推論時に全訓練データとの距離計算が必要なため、サンプル数が増えると遅くなる。組み込みや低リソース環境では Naive Bayes か Logistic が現実的な選択になる。
おわりに
今回の比較で「デフォルト設定でも上位モデルは十分に高精度」という事実が確認できた。それ以上に重要な示唆は、「精度指標だけでモデルを選ぶな」 という点だ。ユースケース・解釈性・推論コスト・更新頻度・チームのスキルセットを総合して選択することが、本当の意味での「良いモデル選択」だと考える。
次回は Cross Validation とハイパーパラメータチューニング(GridSearchCV / Optuna)を加えた続編を予定している。
実行環境: Python 3.11 / scikit-learn 1.x /


コメント