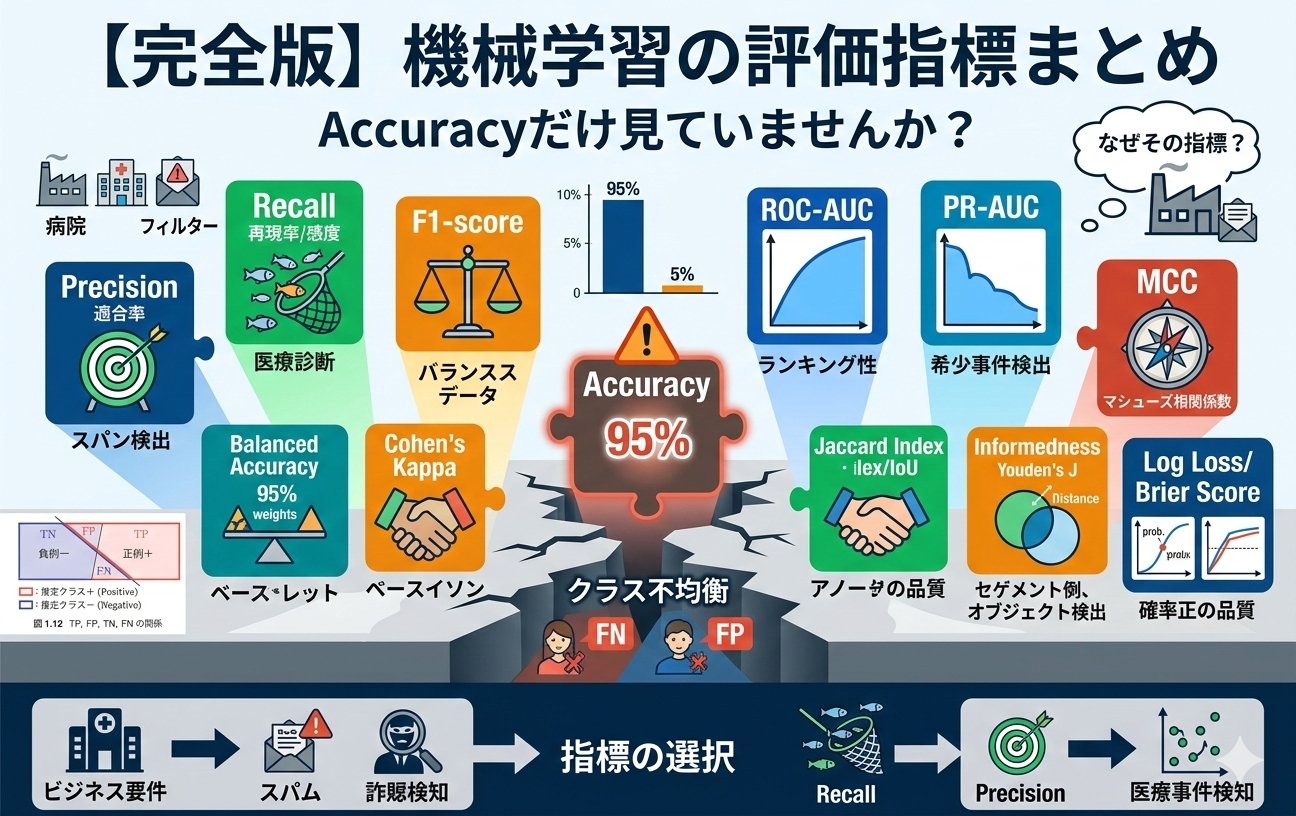
機械学習モデルを評価するとき、多くの人が最初に見るのは Accuracy(正解率) だ。
しかし実務では、「Accuracyは当てにならないケースがある」「データの偏りで評価が大きく歪む」「タスクによって最適な指標が違う」という落とし穴がある。実際、クラス不均衡の問題では、Accuracyが高くてもPrecisionが極端に低いケース、最悪の場合はモデルが「全部陰性と答えるだけ」で高Accuracyを達成してしまうことが起こり得る。
この記事では、基本指標から実務指標、さらにあまり解説されていないマイナー指標まで網羅的に解説する。既存の記事との差別化ポイントは「なぜその指標を使うのか」という設計思想まで踏み込んでいる点だ。
なぜ評価指標が重要なのか
結論から言うと、モデルの「良さ」は指標の選び方で変わる。
例えば医療診断では、見逃し(FN)は致命的で、誤検知(FP)は多少許容できる。つまり、AccuracyよりもRecall重視が合理的だ。一方、スパムフィルタでは、重要なメールを誤ってスパム判定する(FP)方が困る場合が多いので、Precision重視になる。
筆者がモデル比較記事を書くとき、必ず最初に「何を最適化するのか」を決める。指標を後から選ぶのではなく、ビジネス要件から逆算するのが正しい順序だ。この視点が抜けている比較記事は非常に多い。
混同行列(Confusion Matrix)── すべての基礎
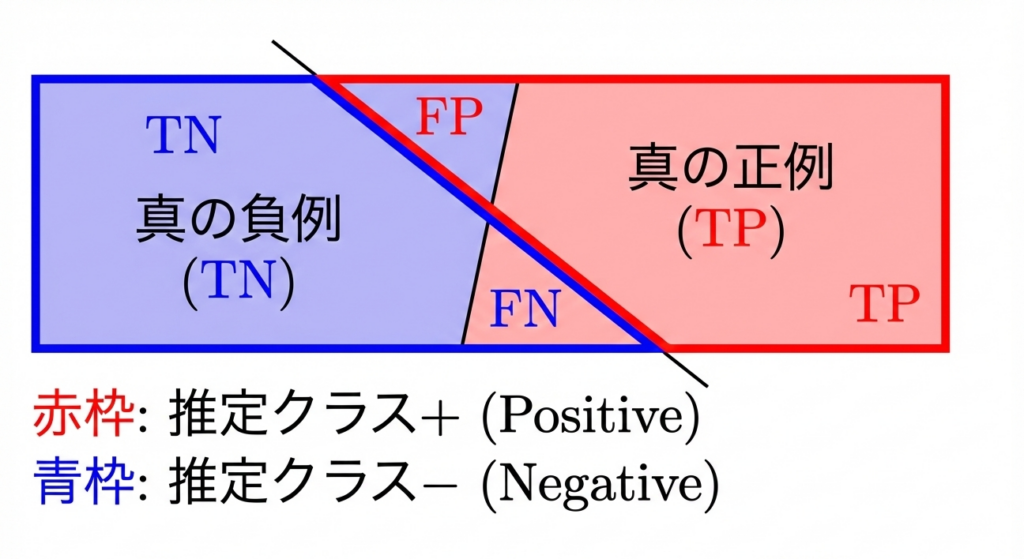
まず評価指標の土台となる混同行列を理解しておく必要がある。
| 予測: Positive | 予測: Negative | |
|---|---|---|
| 実際: Positive | TP(True Positive / 真陽性) | FN(False Negative / 偽陰性) |
| 実際: Negative | FP(False Positive / 偽陽性) | TN(True Negative / 真陰性) |
- TP(True Positive):陽性を正しく陽性と判定
- TN(True Negative):陰性を正しく陰性と判定
- FP(False Positive):陰性を誤って陽性と判定(型1エラー)
- FN(False Negative):陽性を誤って陰性と判定(型2エラー)
以降の全指標はこの4値の組み合わせで定義される。
基本の評価指標
Accuracy(正解率)
最も直感的な指標で、全予測のうち正解した割合。クラスがほぼ同数のベースライン比較では有効だが、不均衡データには弱い。「陰性95%、陽性5%」のデータで全部陰性と答えるだけでAccuracy 95%になってしまう、という有名な落とし穴がある。
使うべき場面: クラスがほぼ同数、ベースライン比較
Precision(適合率)
陽性と予測した中で、本当に陽性だった割合。「陽性と言ったら本当に陽性である確率」とも言える。偽陽性(誤検知)を減らしたい場面で重視する。
使うべき場面: スパム検知、不正検知、誤検知コストが高い場面
Recall(再現率 / 感度 / TPR)
本当に陽性のものをどれだけ拾えたか。「見逃しを減らしたい」場面で重視する。Sensitivityとも呼ばれる。Precisionとトレードオフの関係にあり、閾値を下げるとRecallが上がる代わりにPrecisionが下がる。
使うべき場面: 医療診断、異常検知、見逃しコストが高い場面
Specificity(特異度 / TNR)
陰性を正しく陰性と判定できた割合。Recallが「陽性のうち取りこぼさない力」だとすると、Specificityは「陰性のうち正しく陰性と言える力」だ。医療検査やスクリーニングでは、RecallとSpecificityをセットで報告するのが標準的だ。
使うべき場面: 医療検査、スクリーニング
F1-score
PrecisionとRecallの調和平均。不均衡データでよく使われる。ただし「PrecisionとRecallを同等に重視する」という前提が内包されているため、どちらかを優先したい場合は後述のFβ-scoreの方が適切だ。また閾値依存なので、閾値を変えると値が変わる点も注意が必要。
使うべき場面: 不均衡データ、PrecisionとRecallのバランスを一数値で見たい場面
Fβ-score ─ F1の一般化
F1はβ=1の特殊ケース。βを変えることでRecallとPrecisionの重みづけを調整できる。β>1でRecall重視(見逃しを減らしたい医療向け)、β<1でPrecision重視になる。F2やF0.5がよく使われる。
F1の記事はたくさんあるが、Fβまで解説しているものは少ない。実務ではF1より使い勝手がいい場面も多いので覚えておきたい。
しっかり使える実務指標
ROC-AUC
ROC曲線(Receiver Operating Characteristic curve)は、閾値を0〜1に変化させたときのTPR(Recall)とFPR(= FP / (FP+TN))の軌跡を描いたもの。AUCはその曲線の下面積で、0.5がランダム、1.0が完全識別を意味する。
閾値に依存しないのが最大の強みで、「どの閾値でもスコアの並べ替え精度が高いか」を見ている。前回のBreast Cancerの比較でLinear SVMのAUCが最高だったのも、このランキング性能の高さを示していた。
弱点として、不均衡データでは過大評価されることがある。陰性が多いデータではFPRの分母(TN+FP)が大きくなりFPRが小さく見えるため、ROC曲線が「良く見える」状態になりやすい。
使うべき場面: モデルの総合的なランキング性能の比較、閾値未確定の段階
PR-AUC(Precision-Recall AUC)
PrecisionとRecallの関係を閾値全体で描いた曲線の下面積。ROC-AUCが不均衡データで過大評価されやすい問題に対し、PR-AUCは少数クラスの性能に敏感なためより正直な評価ができる。
筆者の実務経験では、不均衡データで「ROC-AUCは高いのに運用してみると全然検知できない」という現象が何度かあった。その場合、PR-AUCを見ると低かったというケースが多い。不均衡問題では必ずPR-AUCも確認することを強くお勧めする。
使うべき場面: 不均衡データ、医療・不正検知・レアイベント検出
Log Loss(対数損失 / Cross-Entropy Loss)
確率予測の「質」を評価する指標。誤った方向に確信をもって予測するほど大きなペナルティを受ける。例えば「90%の確率で陽性」と予測して実際は陰性だった場合のペナルティは、「55%で陽性」と予測した場合より大幅に大きい。
これが重要なのは、AccuracyやF1は確率の粗さを見抜けないからだ。「0.51でも0.99でも閾値0.5を超えれば同じ予測」として扱う指標では見えない情報が、Log Lossには反映される。確率出力モデルの比較や、Calibration(確率の信頼性)を重視する場面で使う。
使うべき場面: 確率出力モデルの精度評価、アンサンブル学習の最適化
Brier Score
確率予測と真のラベルの二乗誤差の平均。0が完全、1が最悪(すべて逆)。Log Lossより外れ値の影響を受けにくく、解釈が直感的だ。気象予報の精度評価で古くから使われてきた指標でもある。
使うべき場面: 確率キャリブレーションの評価、Log Lossより頑健な評価が必要な場面
上級者向け・マイナー指標
MCC(Matthews Correlation Coefficient)
範囲は -1〜+1 で、+1が完全一致、0がランダム、-1が完全逆。TP・TN・FP・FNすべてを使う二値分類の「最強バランス指標」と呼ばれることがある。
AccuracyやF1と異なり、クラスが不均衡でも意味のある値を返す。バイオ・医療系の論文では標準的に使われており、特にゲノム解析・タンパク質予測の分野で頻出する。筆者の印象では、「ガチで評価をきちんとやっている人」ほどMCCを好む傾向がある。
scikit-learnでは matthews_corrcoef として実装されている。
使うべき場面: 不均衡二値分類、医療・バイオ系論文、厳密な評価が必要な場面
Balanced Accuracy
各クラスのRecallの平均。通常のAccuracyはクラスサイズの影響を受けるが、Balanced Accuracyは各クラスを等重みで評価するため不均衡データに強い。
不均衡分類では、まずAccuracyではなくBalanced Accuracyを見るべきだというのが筆者の意見だ。Balanced Accuracyが0.5ならランダムと同等、1.0なら完全識別なので直感的にも使いやすい。
使うべき場面: 不均衡分類のベースライン評価、Accuracyの改良版が欲しい場面
Cohen’s Kappa(コーエンのカッパ係数)
ここで p_o は観測一致率(Accuracy)、p_e は偶然の一致率。偶然の一致を補正した一致率であり、0が偶然と同等、1が完全一致を意味する。
人 vs AI の比較、医師間の診断一致度測定など、「複数の評価者が同じ対象に独立してラベルをつける」場面で重宝する。アノテーション評価の標準指標として知られているが、機械学習の評価にも使える。
使うべき場面: アノテーション品質評価、人 vs AI 比較、クラス不均衡の補正付き評価
G-Mean(Geometric Mean)
感度(Recall)と特異度(Specificity)の幾何平均。一方が極端に低いと全体の値も下がるため、両クラスのバランスが崩れると厳しいペナルティが入る。不均衡データでも安定した評価が可能で、Balanced Accuracyよりさらにバランスに厳しい指標だ。
scikit-learnには標準実装がないが、imbalanced-learn に含まれている。
使うべき場面: 不均衡データで両クラスのバランスを重視する場面
Jaccard Index(Jaccard係数)
予測陽性と実陽性の「重なり」を集合論的に表した指標。F1とよく似た挙動をするが、TNを考慮しないためセグメンテーションタスクや情報検索でよく使われる。IoU(Intersection over Union)という名前でも知られており、物体検出・画像セグメンテーションの標準指標だ。
使うべき場面: 画像セグメンテーション、物体検出(IoU)、情報検索
Fowlkes-Mallows Index
PrecisionとRecallの幾何平均。F1が調和平均なのに対し、FMは幾何平均を使う。クラスタリング評価でも使われる。F1より極端に低い方の値に敏感な性質がある。
Informedness(Youden’s J)
ROC曲線上でランダム推測からの「距離」を表す指標。Youden’s J statistic とも呼ばれる。0がランダム、1が完全識別。ROC曲線において最適な閾値を選ぶ際の基準としてよく使われる(Jが最大になる点を最適閾値とする)。
使うべき場面: ROC曲線での最適閾値選択、診断精度の報告
Markedness
ここでNPV(Negative Predictive Value)は TN / (TN + FN)。InformedとMarkednessはMCCの分解として理解できる(MCC = √(Informedness × Markedness))。両者を組み合わせるとモデルの性質を多角的に把握できる。
NPV(Negative Predictive Value)
陰性と予測した中で本当に陰性だった割合。Precisionの「陰性版」と考えるとわかりやすい。スクリーニング検査で「陰性と言ったら安心していいか」を評価する際に重要になる。
使うべき場面: 医療スクリーニング、「陰性を見逃さない」ことが重要な場面
Hamming Loss(多ラベル分類)
多ラベル分類(1サンプルに複数ラベルが付く)での評価指標。全ラベルのうち誤ったラベルの割合を表す。テキスト分類(1記事に複数カテゴリが付く)などで使われる。
使うべき場面: 多ラベル分類タスク
Subset Accuracy(多ラベル分類)
多ラベル分類で、すべてのラベルが完全に一致した場合のみ正解とする厳しい指標。「部分的に合っている」を正解と認めないため、Hamming Lossより要求が高い。
回帰タスクの評価指標(参考)
分類とセットで知っておきたい回帰指標も簡単に整理する。
| 指標 | 特徴 |
|---|---|
| MAE | 外れ値に頑健 |
| MSE | 外れ値に敏感 |
| RMSE | 単位がyと同じで解釈しやすい |
| R² | 説明分散の割合、1が完全 |
| MAPE | 相対誤差、ゼロ除算に注意 |
| Huber Loss | MAEとMSEのハイブリッド、外れ値耐性あり |
【実務】どの指標を選ぶべきか
ケース別おすすめ
クラス均衡 × 解釈性重視 → Accuracy + ROC-AUC
不均衡データ(少数クラスを検出したい) → F1 / PR-AUC / MCC(上級)
医療診断(見逃しを最小化したい) → Recall(最重要)+ Specificity + ROC-AUC + NPV
スパム・不正検知(誤検知を最小化したい) → Precision + F1
確率の品質が重要(Calibrationを見たい) → Log Loss + Brier Score
アノテーション評価・人 vs AI → Cohen’s Kappa
画像セグメンテーション・物体検出 → IoU(Jaccard Index)
筆者の実務的な結論
研究・実務を通しての私の結論として、モデル比較で最低限出すべきなのはAccuracy・F1・ROC-AUC・PR-AUCの4つだ。余裕があればMCC・Balanced Accuracy・Log Lossも加えると差別化になる。
それ以上に大切なのは「最初にビジネス要件から逆算して指標を決める」ことだ。精度の数字を最大化することが目的ではなく、「何を間違えたときのコストが高いか」を明確にした上でモデルと指標を選ぶ。これが実務での正しい評価設計だと考えている。
今後のトレンドとして、単一指標での評価はAccuracy単独からAUC系の多指標評価へ確実に移行していくと思う。特に医療AIや金融AIの規制強化が進む中で、この傾向は加速するだろう。
まとめ
本記事で紹介した指標を用途別に整理する。
| カテゴリ | 指標 | 主な用途 |
|---|---|---|
| 基本 | Accuracy, Precision, Recall, F1, Specificity | 全般 |
| F系一般化 | Fβ-score | Recall/Precision重みづけ調整 |
| ランキング系 | ROC-AUC, PR-AUC | モデル比較、不均衡データ |
| 確率の質 | Log Loss, Brier Score | Calibration評価 |
| 不均衡特化 | MCC, Balanced Accuracy, G-Mean | 不均衡分類 |
| 補正系 | Cohen’s Kappa, Informedness, Markedness | アノテーション、閾値選択 |
| 陰性評価 | NPV, Specificity | 医療スクリーニング |
| セグメンテーション | IoU(Jaccard) | 画像系タスク |
| 多ラベル | Hamming Loss, Subset Accuracy | 多ラベル分類 |
関連記事
- scikit-learn 分類器10種を同一条件で比較してみた【Breast Cancer データセット】
- ROC曲線の描き方と閾値調整の実践
- 不均衡データ対策まとめ(オーバーサンプリング・アンダーサンプリング)

コメント