
はじめに
深層学習モデルの訓練において、学習率スケジューラーは訓練の進行に応じて学習率を動的に調整する重要な機能です。固定の学習率を使用するよりも、スケジューラーを活用することで、より早く収束し、より良い性能を達成できることが多くの研究で示されています。
本記事では、PyTorchとTensorFlowで利用可能な主要な学習率スケジューラー(scheduler)について、その特徴と実装方法を詳しく解説します。また、学習率に関して解説している記事はこちら→ 深層学習における学習率の理解と最適化
学習率スケジューラーとは
学習率スケジューラーは、訓練の進行(エポック数やステップ数)に応じて学習率を自動的に調整する仕組みです。一般的に、訓練の初期には大きな学習率で素早く最適解に近づき、後半には小さな学習率で精密に調整することで、より良い収束を実現します。
主要なスケジューラーの種類
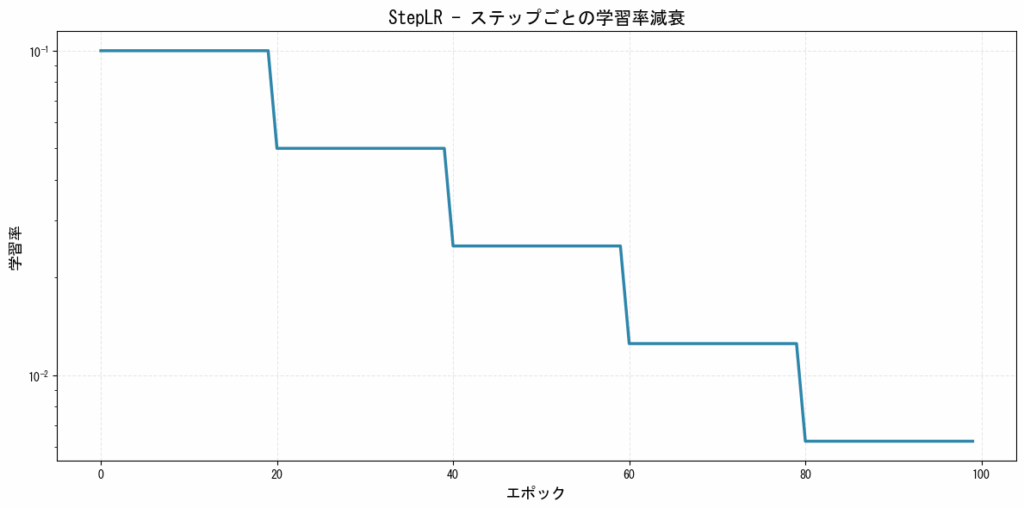
1. StepLR(ステップ減衰)
指定したステップ(エポック)ごとに学習率を一定の割合で減少させるシンプルなスケジューラーです。
特徴:
- 実装が簡単で理解しやすい
- 安定した訓練が可能
- いつ学習率を下げるかの事前知識が必要
[図1: StepLRの学習率推移]
PyTorchでの実装:
import torch.optim as optim
optimizer = optim.Adam(model.parameters(), lr=0.1)
scheduler = optim.lr_scheduler.StepLR(
optimizer,
step_size=20, # 20エポックごとに減衰
gamma=0.5 # 学習率を0.5倍に
)
# 訓練ループ内
for epoch in range(num_epochs):
train(...)
validate(...)
scheduler.step() # エポック終了時に呼び出す
TensorFlowでの実装:
import tensorflow as tf
initial_lr = 0.1
lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
initial_lr,
decay_steps=20,
decay_rate=0.5,
staircase=True # ステップ関数的な減衰
)
optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule)
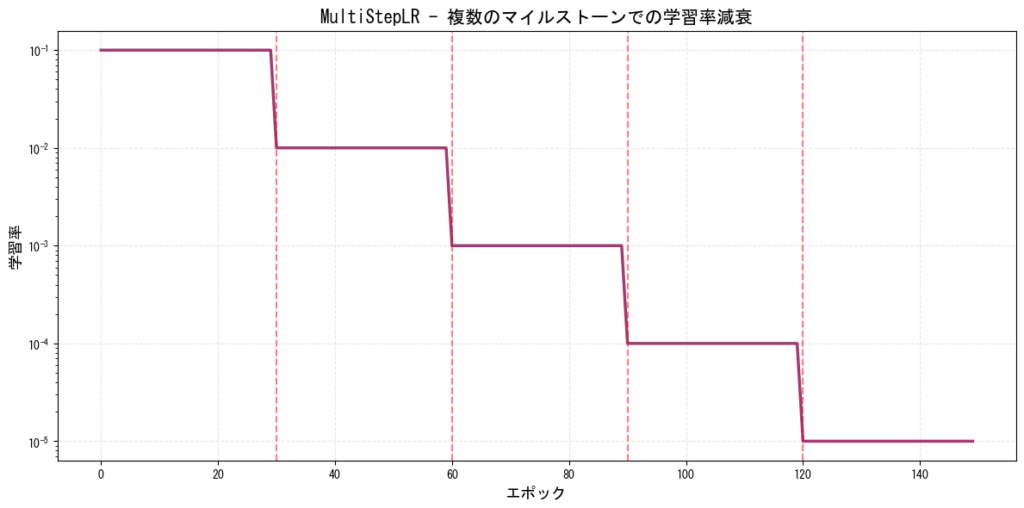
2. MultiStepLR(複数ステップ減衰)
指定した複数のマイルストーンで学習率を減少させるスケジューラーです。StepLRの柔軟版と言えます。Lossが下がらず低迷しているところで手動で学習率を下げれるイメージですね!
特徴:
- 訓練の重要なポイントで学習率を調整可能
- 訓練の各段階で異なる学習率戦略を取れる
- ResNetなどの訓練でよく使用される
[図2: MultiStepLRの学習率推移]
PyTorchでの実装:
scheduler = optim.lr_scheduler.MultiStepLR(
optimizer,
milestones=[30, 60, 90, 120], # 学習率を減衰させるエポック
gamma=0.1 # 各マイルストーンで0.1倍に
)
TensorFlowでの実装:
def multi_step_schedule(epoch, lr):
milestones = [30, 60, 90, 120]
gamma = 0.1
for milestone in milestones:
if epoch >= milestone:
lr *= gamma
return lr
lr_callback = tf.keras.callbacks.LearningRateScheduler(multi_step_schedule)
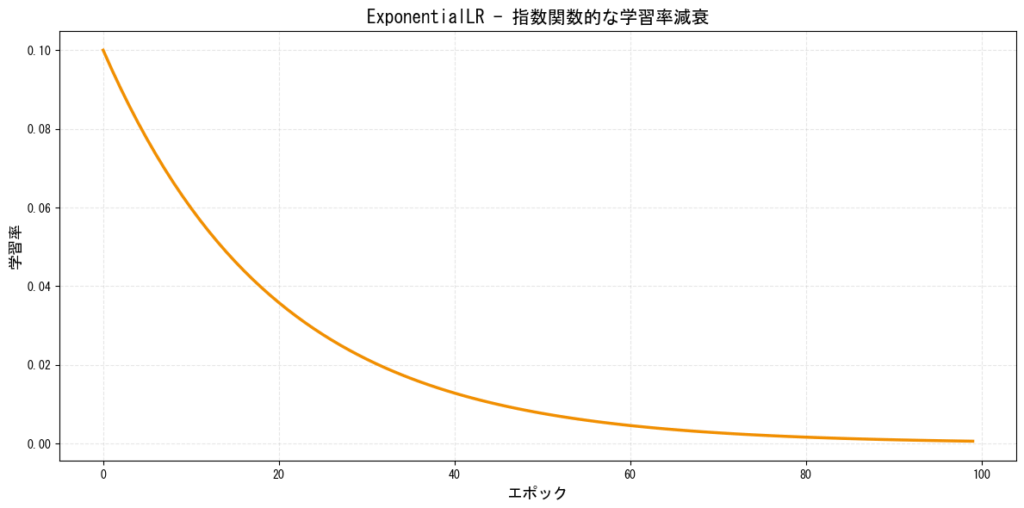
3. ExponentialLR(指数減衰)
学習率を指数関数的に滑らかに減少させるスケジューラーです。
特徴:
- 滑らかな減衰曲線
- 数学的に美しく、理論的な裏付けがある
- 多くのタスクで安定した性能を発揮
[図3: ExponentialLRの学習率推移]
PyTorchでの実装:
scheduler = optim.lr_scheduler.ExponentialLR(
optimizer,
gamma=0.95 # 毎エポック0.95倍に減衰
)
TensorFlowでの実装:
lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate=0.1,
decay_steps=1,
decay_rate=0.95,
staircase=False # 滑らかな減衰
)
optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule)
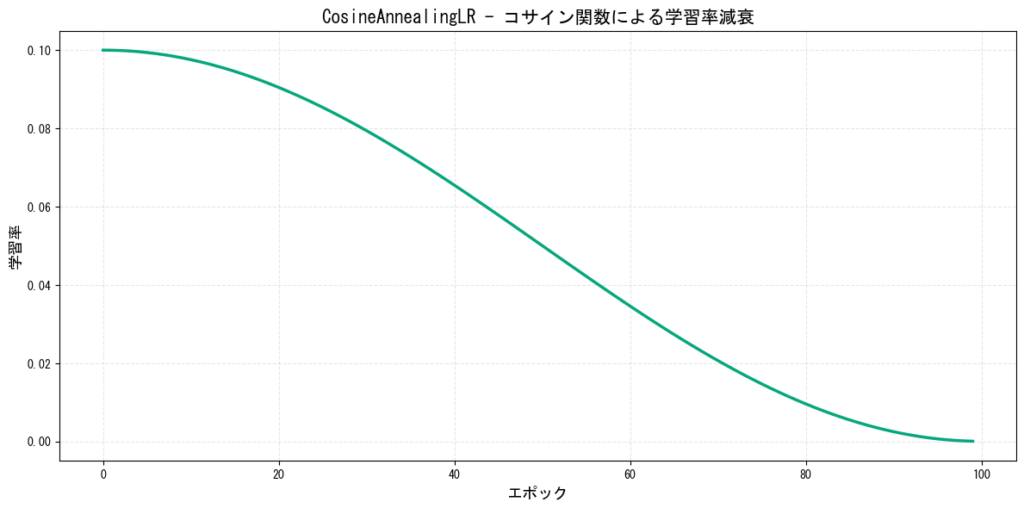
4. CosineAnnealingLR(コサイン減衰)
学習率をコサイン関数に従って減少させるスケジューラーです。画像分類タスクで広く使用されています。
特徴:
- 滑らかで自然な減衰曲線
- 訓練の後半でより細かい調整が可能
- ResNet、EfficientNetなどの訓練で効果的
[図4: CosineAnnealingLRの学習率推移]
PyTorchでの実装:
scheduler = optim.lr_scheduler.CosineAnnealingLR(
optimizer,
T_max=100, # 1周期のエポック数
eta_min=0.0001 # 最小学習率
)
TensorFlowでの実装:
lr_schedule = tf.keras.optimizers.schedules.CosineDecay(
initial_learning_rate=0.1,
decay_steps=100,
alpha=0.0001 # 最小学習率の割合
)
optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule)
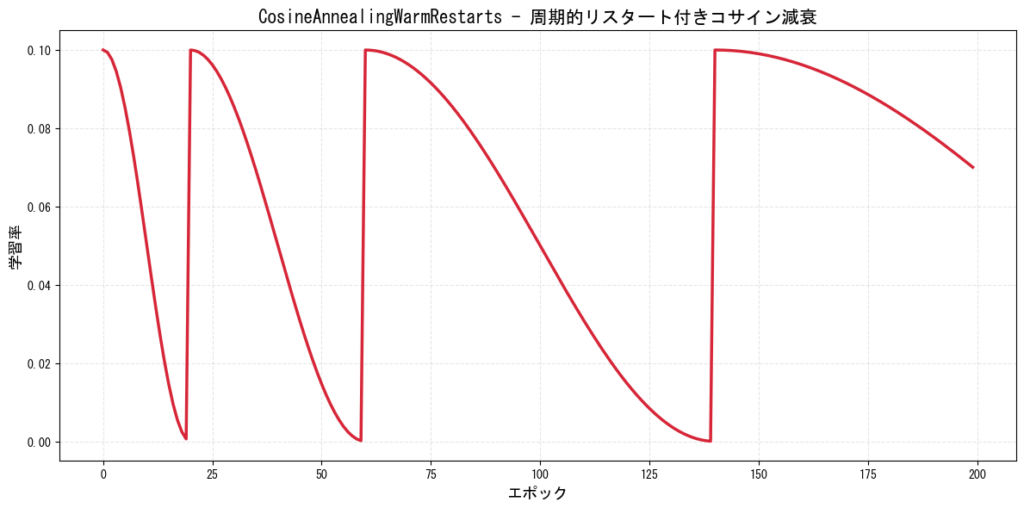
5. CosineAnnealingWarmRestarts(ウォームリスタート付きコサイン減衰)
コサイン減衰に周期的なリスタートを加えたスケジューラーです。SGDR(Stochastic Gradient Descent with Warm Restarts)とも呼ばれます。
特徴:
- 周期的に学習率をリセットすることで局所解から脱出
- リスタートごとに周期を長くできる
- 複雑なタスクで効果を発揮
[図5: CosineAnnealingWarmRestartsの学習率推移]
PyTorchでの実装:
scheduler = optim.lr_scheduler.CosineAnnealingWarmRestarts(
optimizer,
T_0=20, # 最初のリスタート周期
T_mult=2, # リスタート後の周期倍率
eta_min=0.0001
)
# 訓練ループ内で毎エポック呼び出す
for epoch in range(num_epochs):
train(...)
scheduler.step()
TensorFlowでの実装:
# カスタム実装が必要
class CosineAnnealingWarmRestarts(tf.keras.optimizers.schedules.LearningRateSchedule):
def __init__(self, initial_lr, T_0, T_mult=1, eta_min=0):
self.initial_lr = initial_lr
self.T_0 = T_0
self.T_mult = T_mult
self.eta_min = eta_min
def __call__(self, step):
T_cur = step
T_i = self.T_0
while T_cur >= T_i:
T_cur -= T_i
T_i *= self.T_mult
return self.eta_min + (self.initial_lr - self.eta_min) * \
(1 + tf.cos(np.pi * T_cur / T_i)) / 2
lr_schedule = CosineAnnealingWarmRestarts(0.1, T_0=20, T_mult=2)
optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule)
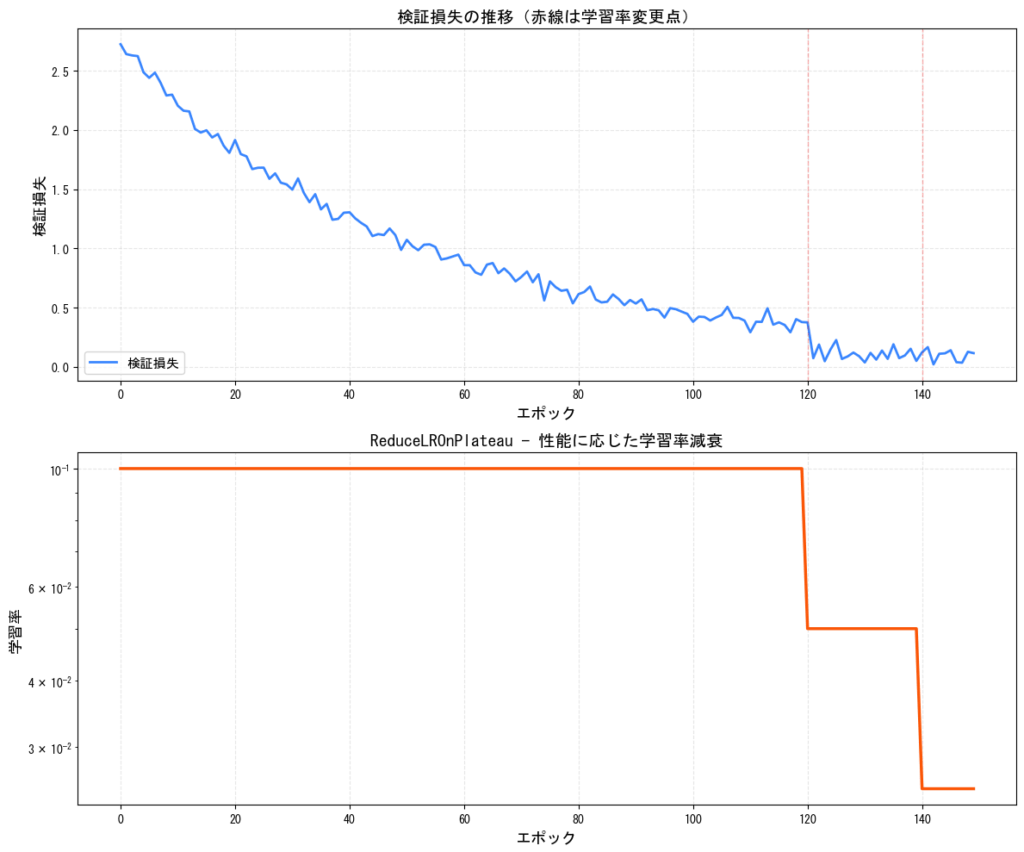
6. ReduceLROnPlateau(性能に応じた減衰)
検証損失が改善しなくなった時に学習率を減少させる適応的なスケジューラーです。図のようにLossが停滞したら学習率を下げることによってさらに再び改善させることができるようになります!
特徴:
- 訓練の進行状況に応じて自動調整
- エポック数を事前に決める必要がない
- 過学習の兆候を検知して学習率を調整
[図6: ReduceLROnPlateauの動作イメージ]
PyTorchでの実装:
scheduler = optim.lr_scheduler.ReduceLROnPlateau(
optimizer,
mode='min', # 'min'は損失を最小化、'max'は精度を最大化
factor=0.5, # 学習率を0.5倍に
patience=10, # 10エポック改善しなかったら減衰
min_lr=1e-6 # 最小学習率
)
# 訓練ループ内
for epoch in range(num_epochs):
train(...)
val_loss = validate(...)
scheduler.step(val_loss) # 検証損失を渡す
TensorFlowでの実装:
reduce_lr_callback = tf.keras.callbacks.ReduceLROnPlateau(
monitor='val_loss', # 監視する指標
factor=0.5, # 学習率を0.5倍に
patience=10, # 10エポック改善しなかったら減衰
min_lr=1e-6,
verbose=1
)
model.fit(x_train, y_train,
validation_data=(x_val, y_val),
callbacks=[reduce_lr_callback])
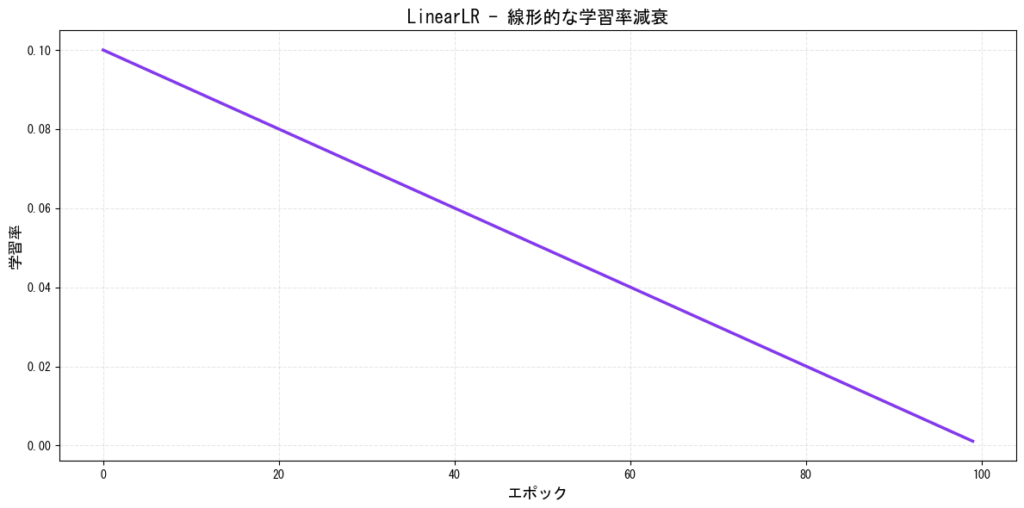
7. LinearLR(線形減衰)
学習率を線形的に減少させるシンプルなスケジューラーです。
特徴:
- シンプルで予測可能な減衰
- ウォームアップとの組み合わせで効果的
- Transformerモデルでよく使用
[図7: LinearLRの学習率推移]
PyTorchでの実装:
scheduler = optim.lr_scheduler.LinearLR(
optimizer,
start_factor=1.0, # 開始時の倍率
end_factor=0.001, # 終了時の倍率
total_iters=100 # 線形減衰を行うエポック数
)
TensorFlowでの実装:
lr_schedule = tf.keras.optimizers.schedules.PolynomialDecay(
initial_learning_rate=0.1,
decay_steps=100,
end_learning_rate=0.0001,
power=1.0 # 1.0で線形減衰
)
optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule)
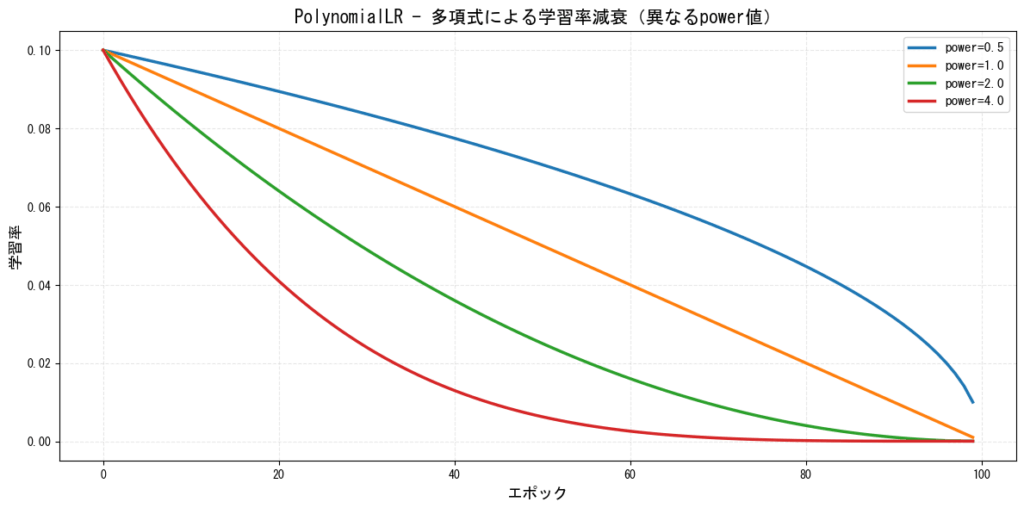
8. PolynomialLR(多項式減衰)
多項式関数を使用して学習率を減少させるスケジューラーです。
特徴:
- 柔軟な減衰曲線を設定可能
- 線形と指数の中間的な挙動
- セグメンテーションタスクなどで使用
[図8: PolynomialLRの学習率推移(異なるpower値)]
PyTorchでの実装:
scheduler = optim.lr_scheduler.PolynomialLR(
optimizer,
total_iters=100, # 減衰を行うエポック数
power=2.0 # 多項式のべき乗
)
TensorFlowでの実装:
lr_schedule = tf.keras.optimizers.schedules.PolynomialDecay(
initial_learning_rate=0.1,
decay_steps=100,
end_learning_rate=0.0001,
power=2.0
)
optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule)
9. LambdaLR(カスタム関数による減衰)
任意の関数を使用して学習率を制御できる柔軟なスケジューラーです。
特徴:
- 完全にカスタマイズ可能
- 複雑な学習率スケジュールを実装可能
- 研究や実験で有用
[図9: LambdaLRのカスタム学習率推移例]
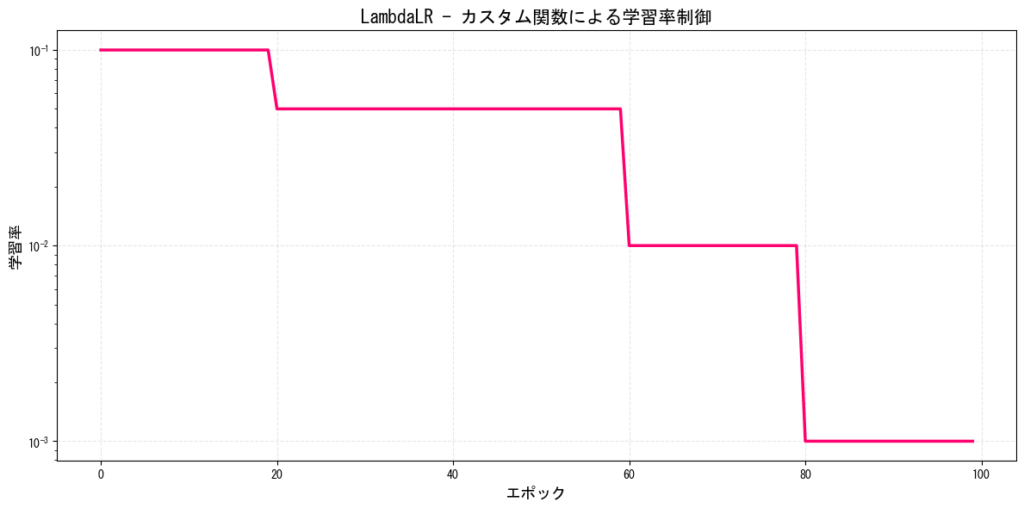
PyTorchでの実装:
def lambda_func(epoch):
if epoch < 20:
return 1.0
elif epoch < 60:
return 0.5
elif epoch < 80:
return 0.1
else:
return 0.01
scheduler = optim.lr_scheduler.LambdaLR(
optimizer,
lr_lambda=lambda_func
)
TensorFlowでの実装:
def custom_schedule(epoch, lr):
if epoch < 20:
return 0.1
elif epoch < 60:
return 0.05
elif epoch < 80:
return 0.01
else:
return 0.001
lr_callback = tf.keras.callbacks.LearningRateScheduler(custom_schedule)
model.fit(x_train, y_train, callbacks=[lr_callback])
10. OneCycleLR(ワンサイクル学習率)
学習率を1回だけ上昇させてから下降させる特殊なスケジューラーです。Super-Convergenceとも呼ばれます。
特徴:
- 非常に高速な収束が可能
- 大きな学習率で正則化効果
- 画像分類で優れた性能
[図10: OneCycleLRの学習率推移]
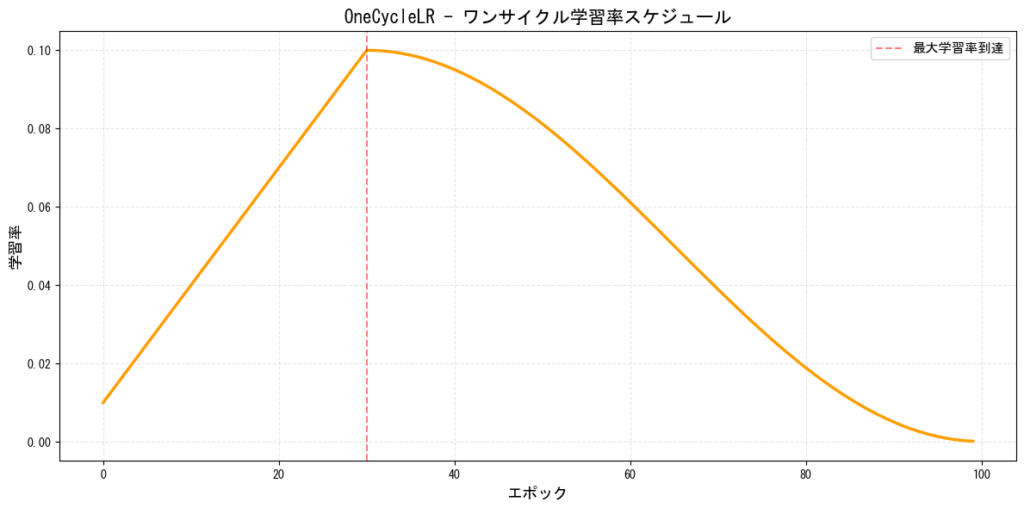
PyTorchでの実装:
scheduler = optim.lr_scheduler.OneCycleLR(
optimizer,
max_lr=0.1, # 最大学習率
total_steps=num_epochs, # 総ステップ数
pct_start=0.3, # 上昇期間の割合
anneal_strategy='cos' # 'cos'または'linear'
)
# 訓練ループ内で毎バッチまたは毎エポック呼び出す
for epoch in range(num_epochs):
for batch in dataloader:
train_step(...)
scheduler.step() # バッチごとに更新
TensorFlowでの実装:
# カスタム実装が必要
class OneCycleLR(tf.keras.optimizers.schedules.LearningRateSchedule):
def __init__(self, max_lr, total_steps, pct_start=0.3):
self.max_lr = max_lr
self.total_steps = total_steps
self.pct_start = pct_start
self.initial_lr = max_lr / 25
self.final_lr = max_lr / 1000
def __call__(self, step):
if step < self.pct_start * self.total_steps:
progress = step / (self.pct_start * self.total_steps)
return self.initial_lr + (self.max_lr - self.initial_lr) * progress
else:
progress = (step - self.pct_start * self.total_steps) / \
((1 - self.pct_start) * self.total_steps)
return self.final_lr + (self.max_lr - self.final_lr) * \
(1 + tf.cos(np.pi * progress)) / 2
lr_schedule = OneCycleLR(max_lr=0.1, total_steps=num_steps)
optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule)
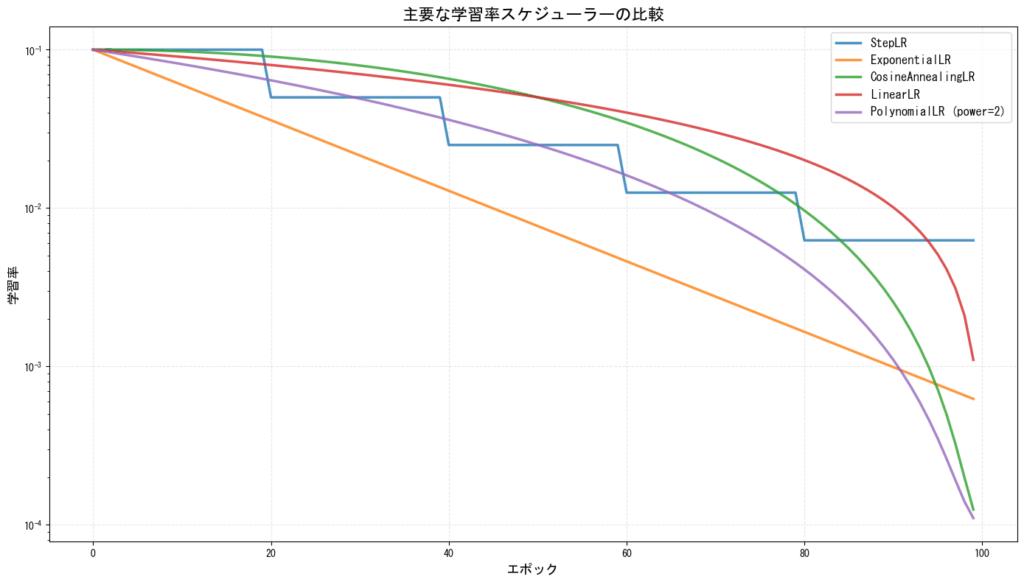
スケジューラーの比較
[図11: 主要スケジューラーの比較]
スケジューラーの組み合わせ(Sequential/Chained)
PyTorchでは複数のスケジューラーを連続して使用することができます。
特徴:
- 訓練の段階に応じて異なる戦略を適用
- ウォームアップ後に別のスケジューラーを使用するなど
- より柔軟な学習率制御
[図12: スケジューラーの組み合わせ例(ウォームアップ→コサイン減衰)]
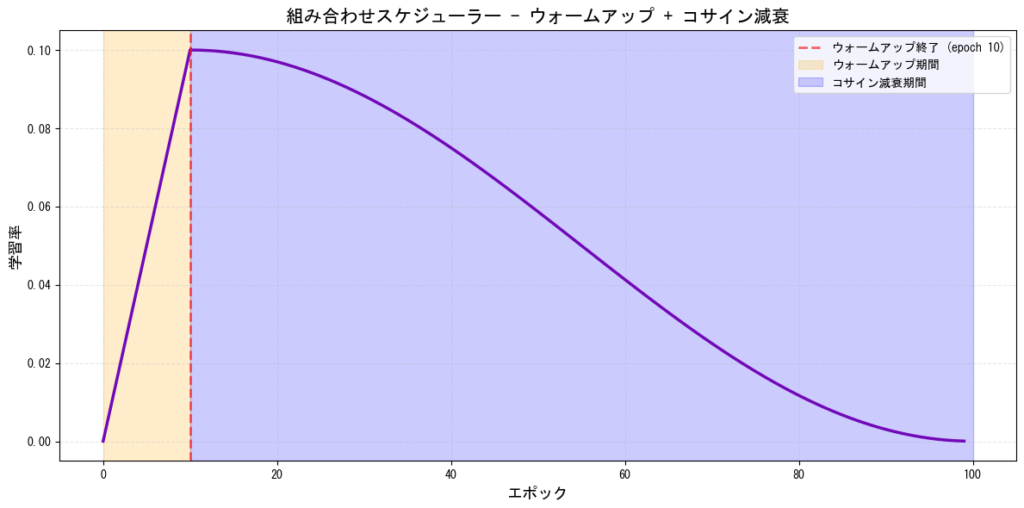
PyTorchでの実装:
# SequentialLRを使用
from torch.optim.lr_scheduler import SequentialLR, LinearLR, CosineAnnealingLR
# ウォームアップスケジューラー
warmup_scheduler = LinearLR(
optimizer,
start_factor=0.001,
end_factor=1.0,
total_iters=10
)
# コサイン減衰スケジューラー
cosine_scheduler = CosineAnnealingLR(
optimizer,
T_max=90,
eta_min=0.0001
)
# 組み合わせ
scheduler = SequentialLR(
optimizer,
schedulers=[warmup_scheduler, cosine_scheduler],
milestones=[10] # 10エポック後に切り替え
)
TensorFlowでの実装:
class WarmupCosineDecay(tf.keras.optimizers.schedules.LearningRateSchedule):
def __init__(self, warmup_steps, total_steps, max_lr, min_lr):
self.warmup_steps = warmup_steps
self.total_steps = total_steps
self.max_lr = max_lr
self.min_lr = min_lr
def __call__(self, step):
if step < self.warmup_steps:
return self.min_lr + (self.max_lr - self.min_lr) * step / self.warmup_steps
else:
progress = (step - self.warmup_steps) / (self.total_steps - self.warmup_steps)
return self.min_lr + (self.max_lr - self.min_lr) * \
(1 + tf.cos(np.pi * progress)) / 2
lr_schedule = WarmupCosineDecay(
warmup_steps=1000,
total_steps=10000,
max_lr=0.1,
min_lr=0.0001
)
optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule)
タスク別推奨スケジューラー
異なるタスクに応じた推奨スケジューラーを以下の表にまとめます。
| タスク | 推奨スケジューラー | 理由 |
|---|---|---|
| 画像分類(CNN) | CosineAnnealingLR, MultiStepLR | ResNetなどで実績があり、安定した収束 |
| 自然言語処理(Transformer) | WarmupCosine, LinearLR | ウォームアップが重要、大規模モデルで効果的 |
| 物体検出 | MultiStepLR, StepLR | COCO訓練で広く使用される標準的手法 |
| セグメンテーション | PolynomialLR, CosineAnnealingLR | 細かい調整が必要なタスクに適合 |
| 生成モデル(GAN) | ReduceLROnPlateau, LinearLR | 不安定な訓練に適応的に対応 |
| 強化学習 | ExponentialLR, ReduceLROnPlateau | 環境に応じて柔軟に調整 |
| 転移学習 | StepLR, ReduceLROnPlateau | 事前学習済みモデルの微調整に適合 |
実践的なヒント
スケジューラー選択のポイント
- 訓練時間が決まっている場合:CosineAnnealingLR、LinearLR
- 訓練時間が未定の場合:ReduceLROnPlateau
- 高速収束が必要な場合:OneCycleLR
- 安定性重視の場合:StepLR、MultiStepLR
- 最先端の性能が必要な場合:ウォームアップ + CosineAnnealingLR
よくある設定ミス
| ミス | 影響 | 対処法 |
|---|---|---|
| scheduler.step()を呼び忘れ | 学習率が更新されない | 訓練ループで毎エポック確実に呼び出す |
| optimizer.step()の前にscheduler.step() | 学習率の更新タイミングがずれる | 必ずoptimizer.step()の後に呼び出す |
| ReduceLROnPlateauに指標を渡さない | スケジューラーが機能しない | scheduler.step(val_loss)と指標を渡す |
| 複数スケジューラーの重複使用 | 予期しない挙動 | 1つのoptimizerに1つのスケジューラー |
デバッグとモニタリング
学習率の推移を記録・可視化することが重要です。
PyTorchでの学習率記録:
# 訓練ループ内
lr_history = []
for epoch in range(num_epochs):
current_lr = optimizer.param_groups[0]['lr']
lr_history.append(current_lr)
print(f'Epoch {epoch}, LR: {current_lr:.6f}')
train(...)
scheduler.step()
TensorFlowでの学習率記録:
# カスタムコールバック
class LRLogger(tf.keras.callbacks.Callback):
def __init__(self):
self.lrs = []
def on_epoch_end(self, epoch, logs=None):
lr = float(tf.keras.backend.get_value(self.model.optimizer.lr))
self.lrs.append(lr)
print(f'Epoch {epoch}, LR: {lr:.6f}')
lr_logger = LRLogger()
model.fit(x_train, y_train, callbacks=[lr_logger])
スケジューラーのハイパーパラメータ調整
各スケジューラーには調整すべきハイパーパラメータがあります。
StepLR / MultiStepLRの調整
| パラメータ | 推奨値 | 調整方法 |
|---|---|---|
| step_size / milestones | 総エポックの1/3〜1/5 | 訓練曲線を見て停滞点を特定 |
| gamma | 0.1〜0.5 | 0.1は標準的、0.5は緩やかな減衰 |
CosineAnnealingLRの調整
| パラメータ | 推奨値 | 調整方法 |
|---|---|---|
| T_max | 総エポック数 | 1周期で完結させるのが一般的 |
| eta_min | 初期学習率の1/100〜1/1000 | 小さすぎると停滞、大きすぎると不安定 |
OneCycleLRの調整
| パラメータ | 推奨値 | 調整方法 |
|---|---|---|
| max_lr | LR Range Testで決定 | 通常の学習率の3〜10倍 |
| pct_start | 0.3 | 0.2〜0.4が一般的 |
まとめ
学習率スケジューラーは深層学習の訓練において非常に重要なツールです。本記事で紹介した各スケジューラーの特徴を理解し、タスクに応じて適切に選択・実装することで、モデルの性能を大きく向上させることができます。
重要ポイント
- タスクに応じたスケジューラー選択:画像分類にはCosineAnnealing、NLPにはウォームアップ付きを推奨
- 適切なハイパーパラメータ設定:デフォルト値から始めて、訓練曲線を見ながら調整
- 学習率の可視化とモニタリング:必ず学習率の推移を記録して確認
- スケジューラーの組み合わせ:ウォームアップと他のスケジューラーの組み合わせは効果的
実際のプロジェクトでは、まず標準的なスケジューラー(CosineAnnealingLRやStepLR)から始め、訓練の様子を観察しながら調整していくことをお勧めします。


コメント