
こんにちは!前回の【Python入門シリーズ⑥】では関数について学習しました。今回はリストと文字列操作について詳しく解説していきます。リストは「複数のデータをまとめて扱う」ための強力なデータ構造で、Pythonプログラミングにおいて最も頻繁に使われる機能の一つです。プログラミングの世界で「買い物リスト」や「ToDoリスト」のようなものを作れるようになります!

このシリーズの目次
このシリーズでは、プログラミングの基礎から始めて、最終的にはAI・機械学習の初歩までを体験できるような構成になっています。
- 第0回: 開発環境の準備 (VS Codeで始めるPython環境構築)
- 第1回: Pythonの特徴とコードの基礎
- 第2回: 変数と型の扱い
- 第3回: 基本的な演算子と演算
- 第4回: 条件分岐の仕方
- 第5回: 繰り返し処理でプログラムを自動化する
- 第6回: 関数を作ってコードを整理整頓する
- 第7回: 複数のデータを扱う「リスト」と文字列操作 ←今ここ
- 第8回: ライブラリでPythonの能力を拡張する
- 第9回: ファイルの読み込みと書き込み
- 第10回: Matplotlib入門!データをグラフで可視化する
- 第11回: 画像データの仕組みとPillowでの基本操作
- 第12回: 画像処理の基礎(フィルタリングと特徴抽出)
- 第13回: 機械学習実践!AIによる画像分類に挑戦
- 第14回: オープンデータの取得と前処理(データクレンジング)
- 第15回: 実践データ分析!オープンデータから傾向を読み解く
リストとは何か?
リストは、複数のデータを順番に並べて1つのまとまりとして扱うデータ構造です。例えば、買い物リストを紙に書くとき「りんご、バナナ、オレンジ」と順番に書きますよね。Pythonのリストも同じように、複数のデータを順序を保ちながら管理できます。
リストの5つの重要な特徴
- 複数の要素を格納: 1個でも100個でも、好きなだけデータを入れられます
- 順序がある: 入れた順番が保持されます。1番目、2番目…と決まっています
- インデックスでアクセス: 番号(0から始まる)で各要素を取り出せます
- 変更可能(ミュータブル): 後から要素を追加したり削除したり変更できます
- 異なる型を混在可能: 数値と文字列を一緒に入れることもできます
なぜこんなに便利かというと、例えば「100人の生徒の点数」を管理したい時、score1, score2, score3...と100個の変数を作る必要がなく、1つのリストで管理できるからです!
リストの作成方法
fruits = ["りんご", "バナナ", "オレンジ"]
numbers = [1, 2, 3, 4, 5]
mixed = [1, "Hello", 3.14, True]
リストは角括弧[]で作ります。中にカンマ,で区切ってデータを並べるだけです。とてもシンプルですね!
リストの基本操作:インデックスとスライス
インデックス(添字)でアクセスする
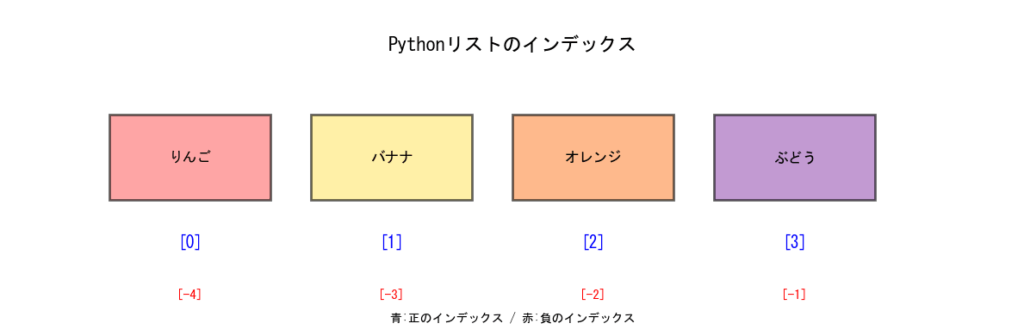
リストの各要素にはインデックスという番号が自動的に付きます。ここで最も重要なのは、Pythonのインデックスは0から始まるということです。
fruits = ["りんご", "バナナ", "オレンジ", "ぶどう"]
print(fruits[0]) # りんご
print(fruits[2]) # オレンジ
なぜ0から始まるのか?これはコンピュータの世界では一般的な慣習です。最初は違和感があるかもしれませんが、すぐに慣れます。これを覚えていないと正しい値が取り出せません!!
重要な注意点: 存在しないインデックスにアクセスするとエラーになります!
# fruits[100] # ❌ エラー!リストには4つしか要素がない
負のインデックス:後ろから数える
Pythonには便利な機能があります。負の数を使うと、後ろから数えることができるんです!
fruits = ["りんご", "バナナ", "オレンジ", "ぶどう"]
print(fruits[-1]) # ぶどう(最後)
print(fruits[-2]) # オレンジ(後ろから2番目)
これは「最後の要素が欲しい」という場合に非常に便利です。リストの長さを知らなくても-1で最後の要素にアクセスできます!
スライス:複数の要素を一度に取り出す
スライスは、リストの一部分を「切り出す」強力な機能です。
numbers = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
print(numbers[2:5]) # [2, 3, 4]
print(numbers[:4]) # [0, 1, 2, 3] (最初から)
print(numbers[5:]) # [5, 6, 7, 8, 9] (最後まで)
print(numbers[::2]) # [0, 2, 4, 6, 8] (2つ飛ばし)
print(numbers[::-1]) # [9, 8, 7, 6, 5, 4, 3, 2, 1, 0] (逆順!)
スライスの文法: [開始:終了:ステップ]
重要なポイント:
- 開始位置は含まれる
- 終了位置は含まれない
- 省略すると最初または最後まで
- ステップは間隔(デフォルトは1)
この「終了位置は含まれない」というのが最初は混乱しやすいですが、「[0:3]で0,1,2の3個取れる」と覚えると分かりやすいです。
リストの要素を変更する
リストの最大の特徴は後から中身を変更できることです。これを専門用語で「ミュータブル(mutable)」と言います。
要素の変更
fruits = ["りんご", "バナナ", "オレンジ"]
fruits[1] = "いちご"
print(fruits) # ['りんご', 'いちご', 'オレンジ']
インデックスを指定して新しい値を代入するだけです。とても直感的ですね!
要素の追加
要素を追加する方法はいくつかあります。状況に応じて使い分けましょう。
fruits = ["りんご", "バナナ"]
# 末尾に追加
fruits.append("オレンジ")
print(fruits) # ['りんご', 'バナナ', 'オレンジ']
# 指定位置に挿入
fruits.insert(1, "いちご")
print(fruits) # ['りんご', 'いちご', 'バナナ', 'オレンジ']
# 別のリストを結合
fruits.extend(["ぶどう", "メロン"])
print(fruits) # ['りんご', 'いちご', 'バナナ', 'オレンジ', 'ぶどう', 'メロン']
使い分けのコツ:
append(): 1つだけ追加したい時(最もよく使う)insert(): 特定の位置に入れたい時extend(): 複数をまとめて追加したい時
要素の削除
削除方法も複数あります。「値を指定」するか「位置を指定」するかで使い分けます。
fruits = ["りんご", "バナナ", "オレンジ", "ぶどう"]
# 値を指定して削除
fruits.remove("オレンジ")
print(fruits) # ['りんご', 'バナナ', 'ぶどう']
# 位置を指定して削除
del fruits[1]
print(fruits) # ['りんご', 'ぶどう']
# 位置を指定して削除&取得
item = fruits.pop(0)
print(item) # りんご
print(fruits) # ['ぶどう']
使い分けのコツ:
remove(): 「バナナを削除」のように値が分かっている時del: 「2番目を削除」のように位置が分かっている時pop(): 削除すると同時にその値を使いたい時
リストの便利なメソッドと関数
Pythonはリストを扱うための便利な機能をたくさん用意してくれています。
よく使うメソッド
numbers = [3, 1, 4, 1, 5, 9, 2]
print(len(numbers)) # 7 (要素数)
print(numbers.count(1)) # 2 (1の出現回数)
print(numbers.index(5)) # 4 (5が最初に見つかる位置)
numbers.sort()
print(numbers) # [1, 1, 2, 3, 4, 5, 9] (昇順ソート)
numbers.reverse()
print(numbers) # [9, 5, 4, 3, 2, 1, 1] (逆順)
sort() の重要な注意点: このメソッドはリスト自体を変更します。元のリストを残したい場合は後述のsorted()関数を使います。
組み込み関数
numbers = [3, 1, 4, 1, 5, 9, 2]
print(len(numbers)) # 7 (要素数)
print(numbers.count(1)) # 2 (1の出現回数)
print(numbers.index(5)) # 4 (5が最初に見つかる位置)
numbers.sort()
print(numbers) # [1, 1, 2, 3, 4, 5, 9] (昇順ソート)
numbers.reverse()
print(numbers) # [9, 5, 4, 3, 2, 1, 1] (逆順)
要素の存在確認
fruits = ["りんご", "バナナ", "オレンジ"]
print("りんご" in fruits) # True
print("ぶどう" in fruits) # False
print("ぶどう" not in fruits) # True
in演算子は、条件分岐と組み合わせてよく使います。
if "バナナ" in fruits:
print("バナナがあります!")
リスト内包表記:リストを簡潔に作る
リスト内包表記(List Comprehension)は、Pythonの最もエレガントな機能の一つです。forループを1行で書けます!
基本的な使い方
まず、従来の方法とリスト内包表記を比較してみましょう。
# 従来の方法:5行
squares = []
for i in range(5):
squares.append(i ** 2)
print(squares) # [0, 1, 4, 9, 16]
# リスト内包表記:1行!
squares = [i ** 2 for i in range(5)]
print(squares) # [0, 1, 4, 9, 16]
どうでしょう?同じ結果が1行で書けました!これがリスト内包表記の威力です。
基本形: [式 for 変数 in イテラブル]
読み方のコツ:「rangeの各iに対して、i**2を計算してリストにする」と後ろから読むと理解しやすいです。こんな風に書けたらかっこいいですね!!
条件付きリスト内包表記
さらに、条件を付けることもできます。
# 偶数だけを2倍にする
numbers = [1, 2, 3, 4, 5, 6]
result = [n * 2 for n in numbers if n % 2 == 0]
print(result) # [4, 8, 12]
# 長い単語だけを大文字化
words = ["cat", "elephant", "dog", "butterfly"]
long_words = [w.upper() for w in words if len(w) > 3]
print(long_words) # ['ELEPHANT', 'BUTTERFLY']
条件付きの形: [式 for 変数 in イテラブル if 条件]
これは「条件を満たすものだけ処理する」フィルタリングです。
if-elseを使った条件分岐
# 偶数は2倍、奇数は3倍
numbers = [1, 2, 3, 4, 5]
result = [n * 2 if n % 2 == 0 else n * 3 for n in numbers]
print(result) # [3, 4, 9, 8, 15]
if-elseの形: [式A if 条件 else 式B for 変数 in イテラブル]
注意:if-elseの場合、位置が異なります!forの前に書きます。
使い分けのポイント:
- フィルタリング(一部だけ選ぶ):
ifだけを使い、forの後に書く - 条件分岐(全部処理するが結果が変わる):
if-elseを使い、forの前に書く
タプル:変更できないリスト
タプル(tuple)は、リストとよく似ていますが一度作ったら変更できないという重要な違いがあります。
タプルの作成と使用
# タプルは丸括弧で作る
coordinates = (3, 5)
rgb = (255, 128, 0)
# アクセスはリストと同じ
print(coordinates[0]) # 3
print(rgb[-1]) # 0
# 変更しようとするとエラー!
# coordinates[0] = 10 # ❌ TypeError!
タプルのアンパック
タプルの便利な機能としてアンパックがあります。複数の変数に一度に代入できます!
coordinates = (3, 5)
x, y = coordinates
print(f"x={x}, y={y}") # x=3, y=5
# 関数で複数の値を返す時によく使う
def get_name_age():
return "太郎", 25
name, age = get_name_age()
print(name, age) # 太郎 25
タプルとリストの使い分け
どちらを使うべきか迷った時の判断基準:
タプルを使うべき時:
- 座標(x, y)や日付(年, 月, 日)など、固定されたデータ
- 変更されたくないデータ(設定値、定数など)
- 辞書のキーとして使いたい時(リストは不可)
- 少しでもメモリを節約したい時
リストを使うべき時:
- ユーザーリスト、商品リストなど、要素が増減する可能性がある
- 後から並び替えたりフィルタリングしたい
- 同じ種類のデータの集まり
基本的には「変更する可能性があるならリスト、変更しないならタプル」と覚えておけばOKです!
文字列操作の基礎
実は、文字列もリストと似た性質を持っています。インデックスやスライスが使えるんです!
文字列のインデックスとスライス
text = "Python"
print(text[0]) # P
print(text[-1]) # n
print(text[0:3]) # Pyt
print(text[::-1]) # nohtyP(逆順!)
print(len(text)) # 6
リストとまったく同じ感覚で使えますね!
文字列は変更不可(イミュータブル)
ただし、リストとの大きな違いがあります。文字列は変更できません!
text = "Python"
# text[0] = "J" # ❌ エラー!
# 新しい文字列を作る必要がある
text = "J" + text[1:]
print(text) # Jython
この「変更できない」という性質は、タプルと同じです。文字列を「文字のタプル」だと考えると分かりやすいかもしれません。
文字列の便利なメソッド
文字列には、様々な操作をするためのメソッドが用意されています。よく使うものを厳選して紹介します!
大文字・小文字の変換
text = "Hello World"
print(text.upper()) # HELLO WORLD(全て大文字)
print(text.lower()) # hello world(全て小文字)
print(text.title()) # Hello World(単語の先頭を大文字)
これらは、ユーザーが入力したデータを統一する時などに使います。例えば、メールアドレスの比較は大文字小文字を区別しないので、全て小文字に変換してから比較したりします。
文字列の検索
text = "Python Programming"
print("Python" in text) # True
print(text.startswith("Python")) # True(〜で始まる)
print(text.endswith("ing")) # True(〜で終わる)
print(text.find("Pro")) # 7(見つかった位置)
print(text.find("Java")) # -1(見つからない)
print(text.count("o")) # 2(oの出現回数)
find()は見つからない時に-1を返します。エラーにならないので安全です。
文字列の分割と結合
これは最も重要で頻繁に使う操作です!
# split:文字列→リスト
text = "りんご,バナナ,オレンジ"
fruits = text.split(",")
print(fruits) # ['りんご', 'バナナ', 'オレンジ']
sentence = "Python is awesome"
words = sentence.split() # 引数なしは空白で分割
print(words) # ['Python', 'is', 'awesome']
# join:リスト→文字列
fruits = ["りんご", "バナナ", "オレンジ"]
text = "、".join(fruits)
print(text) # りんご、バナナ、オレンジ
重要なポイント:
split()は文字列をリストに分割join()はリストを文字列に結合- CSVデータの処理やログの解析で必須のテクニック!
空白の削除
ユーザー入力を処理する時に必須の操作です。
text = " Hello World "
print(text.strip()) # "Hello World"(両端の空白削除)
print(text.lstrip()) # "Hello World "(左だけ)
print(text.rstrip()) # " Hello World"(右だけ)
なぜ重要かというと、ユーザーが余分なスペースを入力してしまうことはよくあるからです。
# ユーザー入力の例
email = input("メールアドレス: ") # "user@example.com " (末尾にスペース!)
email = email.strip() # スペースを削除
文字列の置換
text = "I like apples"
new_text = text.replace("apples", "oranges")
print(new_text) # I like oranges
# 置換回数を指定
text = "one two one three one"
result = text.replace("one", "ONE", 2) # 最初の2回だけ
print(result) # ONE two ONE three one
replace()は新しい文字列を返します。元の文字列は変わりません(イミュータブルなので)。
文字列のチェック
文字列の内容を確認するメソッドです。入力検証で使います。
print("123".isdigit()) # True(数字だけ?)
print("abc".isalpha()) # True(アルファベットだけ?)
print("abc123".isalnum()) # True(英数字だけ?)
print("hello".islower()) # True(全て小文字?)
print("HELLO".isupper()) # True(全て大文字?)
これらは、パスワードの強度チェックやフォーム入力の検証に使われます。
文字列のフォーマット
変数を文字列に埋め込む方法を学びましょう。Pythonには複数の方法がありますが、f-stringが最も現代的で読みやすい方法です。
f-string(推奨!)
name = "太郎"
age = 25
# 変数を{}で囲む
message = f"{name}さんは{age}歳です"
print(message) # 太郎さんは25歳です
# 式も埋め込める
print(f"{age}歳は{age * 12}ヶ月です")
# 小数点以下の桁数指定
pi = 3.14159265
print(f"円周率: {pi:.2f}") # 円周率: 3.14
f-stringの読み方: 文字列の前にfをつけ、変数を{}で囲むだけ。とてもシンプルです!
他の方法(参考)
# format()メソッド
print("{}さんは{}歳です".format("花子", 30))
# %演算子(古い方法)
print("%sさんは%d歳です" % ("次郎", 28))
これらも動きますが、新しいコードではf-stringを使うのが標準です。読みやすさが全然違います!
実践例:データ処理
ここまで学んだ知識を使って、実際のデータ処理に挑戦しましょう。
例1:CSVデータの簡易処理
CSV(Comma-Separated Values)は、データを扱う上で最も基本的なフォーマットです。
csv_data = """名前,年齢,都市
太郎,25,東京
花子,30,大阪
次郎,28,福岡"""
lines = csv_data.strip().split("\n")
header = lines[0].split(",")
data_lines = lines[1:]
for line in data_lines:
values = line.split(",")
print(f"{values[0]}さん({values[1]}歳) - {values[2]}")
処理の流れ:
- 行ごとに分割(
split("\n")) - 各行をカンマで分割(
split(",")) - データを取り出して整形
この基本パターンは、ログファイルやデータファイルの処理でよく使います。
例2:ログデータの分析
実際のシステムで生成されるログを分析してみましょう。
logs = [
"2025-01-15 10:23:45 INFO User logged in",
"2025-01-15 10:24:12 ERROR Database connection failed",
"2025-01-15 10:25:03 INFO Page viewed",
"2025-01-15 10:26:18 WARNING Memory usage high",
"2025-01-15 10:27:32 ERROR File not found",
]
# エラーだけを抽出
errors = [log for log in logs if "ERROR" in log]
print(f"総ログ数: {len(logs)}")
print(f"エラー数: {len(errors)}")
# 各エラーの詳細を表示
for error in errors:
parts = error.split(" ", 3) # 最大3回分割
date, time, level, message = parts
print(f" [{date} {time}] {message}")
解説:
split(" ", 3)で最大3回だけ分割。メッセージ部分にスペースがあっても大丈夫!- リスト内包表記で条件に合うログだけ抽出
- 大量のログから問題を素早く見つけられる
例3:テキストの単語頻度分析
text = "Python is great. Python is easy. Python is powerful."
# 単語に分割して小文字化
words = text.lower().replace(".", "").split()
# 頻度をカウント
word_count = {}
for word in words:
word_count[word] = word_count.get(word, 0) + 1
# 頻度順にソート
sorted_words = sorted(word_count.items(), key=lambda x: x[1], reverse=True)
for word, count in sorted_words[:5]: # トップ5
print(f"{word}: {count}回")
ポイント:
get()メソッドで存在しないキーにも安全にアクセスsorted()でソート、lambdaでソート基準を指定- 自然言語処理の基礎となるテクニック
辞書(Dictionary)との組み合わせ
ここで、もう一つ重要なデータ構造辞書を紹介します。リストと組み合わせると非常に強力です!
辞書の基本
辞書は「キー」と「値」のペアでデータを管理します。電話帳をイメージしてください。名前(キー)から電話番号(値)を引けますよね。
person = {
"name": "太郎",
"age": 25,
"city": "東京"
}
print(person["name"]) # 太郎
print(person.get("age")) # 25
person["job"] = "エンジニア" # 追加
リストとの違い:
- リスト: 番号(0, 1, 2…)で値を管理
- 辞書: 任意のキー(“name”, “age”など)で値を管理
辞書のリスト:実データの管理
実際の業務では、複数のデータをこのように管理します。
students = [
{"name": "太郎", "score": 85},
{"name": "花子", "score": 92},
{"name": "次郎", "score": 78},
]
# 平均点を計算
average = sum([s["score"] for s in students]) / len(students)
print(f"平均点: {average:.1f}")
# 80点以上の学生
high_scorers = [s for s in students if s["score"] >= 80]
print(f"80点以上: {[s['name'] for s in high_scorers]}")
# 成績順にソート
sorted_students = sorted(students, key=lambda s: s["score"], reverse=True)
for i, student in enumerate(sorted_students, 1):
print(f"{i}位: {student['name']} ({student['score']}点)")
なぜ辞書を使うのか?
- データの意味が明確(
students[0][1]よりstudents[0]["score"]の方が分かりやすい) - 項目の追加・削除が容易
- 実際のJSON APIやデータベースと同じ構造
AIとの関連性
リストと文字列操作は、AI・機械学習の基礎中の基礎です。全てのデータ処理はここから始まります。
データセットの管理
機械学習では、数千〜数百万のデータをリストで管理します。
# 画像分類の訓練データ(概念的な例)
training_data = [
{"image": "cat_001.jpg", "label": "cat"},
{"image": "dog_001.jpg", "label": "dog"},
{"image": "cat_002.jpg", "label": "cat"},
# ... 膨大なデータ
]
# ラベルごとに集計
def count_by_label(data):
counts = {}
for item in data:
label = item["label"]
counts[label] = counts.get(label, 0) + 1
return counts
print(count_by_label(training_data))
# {'cat': 2, 'dog': 1}
なぜ重要か?
- データの偏りを確認(犬の画像が少ない、など)
- 訓練データとテストデータの分割
- バッチ処理(一度に複数データを処理)
自然言語処理(NLP)の前処理
AIで文章を理解させるには、まず文章を「処理しやすい形」に変換する必要があります。
def preprocess_text(text):
# 小文字化
text = text.lower()
# 句読点削除
text = text.replace(".", "").replace(",", "")
# 単語に分割
words = text.split()
# ストップワード削除(意味の薄い単語)
stop_words = ["the", "a", "is", "are"]
words = [w for w in words if w not in stop_words]
return words
text = "The cat is sleeping on a mat."
print(preprocess_text(text))
# ['cat', 'sleeping', 'on', 'mat']
AI開発での流れ:
- 前処理: 不要な情報を削除、形式を統一
- トークン化: 文章を単語に分割
- ベクトル化: 単語を数値に変換
- モデルに入力: AIが学習・予測
ワンホットエンコーディング
カテゴリデータ(犬、猫、鳥など)を数値に変換する基本技術です。
labels = ["cat", "dog", "bird"]
def one_hot_encode(label, all_labels):
encoding = [0] * len(all_labels)
index = all_labels.index(label)
encoding[index] = 1
return encoding
for label in labels:
print(f"{label}: {one_hot_encode(label, labels)}")
# cat: [1, 0, 0]
# dog: [0, 1, 0]
# bird: [0, 0, 1]
なぜ必要か? AIは数値しか理解できません。「犬」という文字をそのまま入力できないので、[0, 1, 0]のような数値に変換する必要があります。
よくあるエラーとその対策
初心者がよく遭遇するエラーと、その解決方法を見ていきましょう。
1. IndexError: list index out of range
fruits = ["りんご", "バナナ"]
# print(fruits[5]) # ❌ エラー!
原因: 存在しないインデックスにアクセスしようとしている
解決方法:
# リストの長さを確認
if len(fruits) > 5:
print(fruits[5])
else:
print("インデックス5は存在しません")
# 最後の要素が欲しい場合
print(fruits[-1]) # 負のインデックスが安全
教訓: リストのインデックスは0からlen(リスト)-1までです!
2. ValueError: list.remove(x): x not in list
fruits = ["りんご", "バナナ"]
# fruits.remove("ぶどう") # ❌ エラー!
原因: 存在しない要素を削除しようとしている
解決方法:
if "ぶどう" in fruits:
fruits.remove("ぶどう")
else:
print("ぶどうは存在しません")
教訓: 削除前にinで存在確認!
3. TypeError: ‘str’ object does not support item assignment
text = "Python"
# text[0] = "J" # ❌ エラー!
原因: 文字列は変更できない(イミュータブル)
解決方法:
text = "J" + text[1:] # 新しい文字列を作成
print(text) # Jython
教訓: 文字列は読み取り専用。変更したい場合は新しい文字列を作る!
4. TypeError: can only concatenate list (not “int”) to list
numbers = [1, 2, 3]
# result = numbers + 4 # ❌ エラー!
原因: リストに単一要素を直接追加できない
解決方法:
numbers.append(4) # 方法1
result = numbers + [4] # 方法2(リストとして結合)
教訓: +演算子はリスト同士の結合。単一要素ならappend()!
5. KeyError: 辞書のキーが存在しない
person = {"name": "太郎"}
# print(person["age"]) # ❌ エラー!
原因: 存在しないキーにアクセス
解決方法:
# getメソッドが安全
age = person.get("age", 0) # 存在しなければ0
# 存在確認
if "age" in person:
print(person["age"])
教訓: 辞書にはget()を使う習慣をつけよう!
練習問題
理解を深めるため、以下の問題に挑戦してみましょう!
問題1: リストの基本操作
以下の関数を作成してください:
remove_duplicates(lst): 重複を削除した新しいリストを返すfind_common(list1, list2): 2つのリストの共通要素を返す
例:
print(remove_duplicates([1, 2, 2, 3, 3, 3])) # [1, 2, 3]
print(find_common([1, 2, 3], [2, 3, 4])) # [2, 3]
ヒント: set()を使うと重複が自動的に削除されます
問題2: 文字列変換
以下の関数を作成してください:
reverse_words(text): 単語の順序を逆にするis_palindrome(text): 回文(前から読んでも後ろから読んでも同じ)か判定
例:
print(reverse_words("Hello World")) # "World Hello"
print(is_palindrome("madam")) # True
print(is_palindrome("hello")) # False
ヒント:
reverse_words:split()と[::-1]を使用is_palindrome: 文字列と逆順を比較
問題3: データ集計
売上データから統計を計算してください:
sales = [
{"product": "りんご", "amount": 1500},
{"product": "バナナ", "amount": 1200},
{"product": "りんご", "amount": 1800},
]
作成する関数:
total_sales(sales): 総売上sales_by_product(sales): 商品別売上を辞書で返す
期待される出力:
print(total_sales(sales)) # 4500
print(sales_by_product(sales)) # {'りんご': 3300, 'バナナ': 1200}
問題4: リスト内包表記
リスト内包表記を使って以下を実装:
- 1〜100の3の倍数リスト
- 文字列リストから長さ5以上を抽出して大文字化
- 辞書内包表記で{0: 0, 1: 1, 2: 4, …, 9: 81}を作成
ヒント:
# 1. [n for n in range(...) if ...]
# 2. [w.upper() for w in words if ...]
# 3. {i: i**2 for i in range(...)}
問題5: テキスト分析
以下の機能を持つ関数を作成:
def analyze_text(text):
"""
返す辞書:
- 文字数(スペース含む)
- 文字数(スペース除く)
- 単語数
- 最も長い単語
"""
pass
テストデータ:
text = "Python is a powerful language"
result = analyze_text(text)
# {'chars_with_space': 29, 'chars_no_space': 24,
# 'words': 5, 'longest_word': 'powerful'}
まとめ
今回はリストと文字列操作について学習しました。重要なポイントをおさらいします:
リストの重要ポイント
- 作成:
[]で作る、複数の要素を格納 - アクセス: インデックスは0から、負の値で後ろから
- スライス:
[開始:終了:ステップ]で範囲指定 - 変更可能: append, insert, remove, popで編集
- 便利機能: len, sum, max, min, sorted
- 内包表記:
[式 for 変数 in イテラブル]で簡潔に作成
文字列の重要ポイント
- 性質: リストに似ているが変更不可
- 分割:
split()で文字列→リスト - 結合:
join()でリスト→文字列 - 変換: upper, lower, strip, replace
- 検索: find, startswith, endswith, count
- フォーマット: f-stringで変数埋め込み
タプルと辞書
- タプル: 変更不可のリスト、
()で作成 - 辞書: キーと値のペア、
{}で作成 - 組み合わせ: リスト+辞書で複雑なデータ管理
AIでの重要性
- データセット管理の基礎
- テキスト前処理は全てここから
- データ変換・エンコーディング
- 実務で最も使う技術の一つ
リストと文字列をマスターすれば、データの整理・加工・分析が自由自在になります。これはプログラミングの土台であり、AI・機械学習でも毎日使う技術です。しっかり練習して身につけましょう!
次回予告
第8回では「ライブラリでPythonの能力を拡張する」として、外部ライブラリの使い方を学習します。NumPy、Pandas、Matplotlibなど、データサイエンスに必須のライブラリの導入方法と基本的な使い方を習得していきます。ここから一気に実践的になりますよ!お楽しみに!


コメント